Torchvision Object Detection Finetuning Tutorial
torchvision object detection finetuning tutorial
1. はじめに
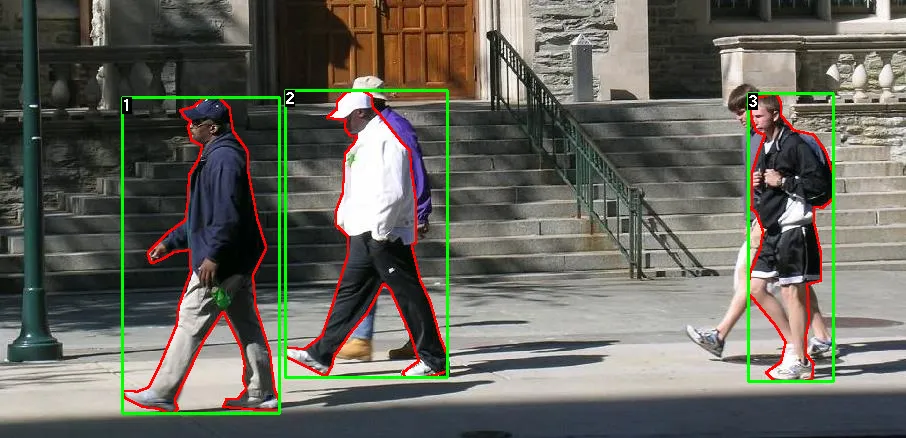
この勉強会では、Penn-Fudan Database for Pedestrian Detection and Segmentationを用いて訓練済みのMask R-CNNをファインチューニングするところまで行います。
Penn-Fudan Database for Pedestrian Detection and Segmentatioとは、170枚の画像と345個の歩行者のインスタンスを含むデータセットになります。
勉強会の流れはこちらになります。
- PennFudanPedをダウンロード
torch.utils.data.Datasetを用いてデータセットの作成- Faster R-CNNを用いて、maskを予測するモデルを作成
- augumentationの定義
- 学習
- 推論
2. データセットの定義
データセットを作成する場合、torch.utils.data.Datasetを継承し、__len__と__getitem__を実装する必要があります。
- image : サイズが
(H, W)のPIL画像 - target : 以下の情報を含む辞書型データ
-
boxes(
FloatTensor[N, 4]) : N個のバウンディングボックスの座標([x0, y0, x1, y1])。値の範囲は、0からW、0からH。 -
labels(
Int64Tensor[N]) : 各バウンディングボックスのラベル。0は背景のクラス。 -
image_id(
Int64Tensor[1]) : 画像識別子。データセットにおいて一意であり、評価時に使用される。 -
area(
Tensor[N]) : バウンディングボックスの領域。COCO metricで評価する際に、小サイズの箱、中サイズの箱、大サイズの箱の間で指標スコアを分けるために使用する。 -
iscrowd(
UInt8Tensor[N]) :iscrowd=Trueの際、評価時に無視される。 -
(optionally) masks(
UInt8Tensor[N, H, W]) : オブジェクト毎のセグメンテーションマスク。 -
(optionally) keypoints(
FloatTensor[N, K, 3]) : N個のオブジェクトのそれぞれについて、オブジェクトを定義するK個のキーポイントが[x, y, visibility]で格納されている。visibility=0はキーポイントが表示されないことを意味している。
-
boxes(
0を背景として扱います。使用するデータセットが背景クラスを含んでいない場合、ラベルの中に
0を含まないようにしてください。例えば、犬猫の2クラスのデータセットを想定している場合、猫に対しては
1、犬に対しては2を指定します。もし、一枚の画像に両方が写っているのなら、
labelsは[1, 2]となります。また、座標ではなくアスペクト比を使用する場合は、
get_height_and_width関数を定義し、画像におけるwidthとheightを返すようにします。
1. データセットをダウンロードします。
unzip PennFudanPed.zip
# PennFudanPedの構造
PennFudanPed/
PedMasks/
FudanPed00001_mask.png
FudanPed00002_mask.png
FudanPed00003_mask.png
FudanPed00004_mask.png
...
PNGImages/
FudanPed00001.png
FudanPed00002.png
FudanPed00003.png
FudanPed00004.png
2. PennFudanDatasetクラスを定義します。
# PennFudanDatasetクラスの定義
import os
import numpy as np
import torch
from PIL import Image
class PennFudanDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms):
self.root = root
self.transforms = transforms
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages")))) # ex) FudanPed00001.png
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks)))) # ex) FudanPed00001_mask.png
def __getitem__(self, idx):
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx]) # ex) root/PNGImages/FudanPed00001.png
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx]) # ex) root/PedMasks/FudanPed00001_mask.png
img = Image.open(img_path).convert('RGB')
mask = Image.open(mask_path)
mask = np.array(mask)
obj_ids = np.unique(mask)
obj_ids = obj_ids[1:] # obj_ids[0] is 0.
masks = mask == obj_ids[:, None, None] # ex) if obj_ids == 2 -> masks shape : [2, H, W]
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.nonzero(masks[i]) # np.nonzero : ゼロでない要素のインデックスを返す。二次元arrayの場合、各軸方向にtuppleでreturn
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target['boxes'] = boxes
target['labels'] = labels
target['masks'] = masks
target['image_id'] = image_id
target['area'] = area
target['iscrowd'] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
3. モデルの定義
このチュートリアルでは、Mask R-CNNを使用します。Mask R-CNNは、Faster R-CNNをベースとし、物体検出とセグメンテーションを同時に行うモデルになります。 このセグメンテーションはSemantic Segmentationではなく、Instance Segmentationを指すそうです。(詳しくはこちら)
- Semantic Segmentation : どのカテゴリーに属するかでピクセルを分類する。一つの画像に人が複数写っている場合、全て人としてマスクが作成される。
- Instance Segmentation : どのカテゴリーに属するか、インスタンス毎にピクセルを分類する。一つの画像に人が複数写っている場合、それぞれの人に別のラベルを付与する。
2015年にMicrosoftが開発した物体検出モデル。
- ある矩形の中身が物体なのか背景(何も写っていない)なのか。(Region Proposal Networkを用いる。)
- 検出した場所に、具体的に何が写っているのかを学習。
# セグメンテーションマスクを予測するモデルの定義
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_model_instance_segmentation(num_classes):
# resnet50を特徴抽出モデルと使用した事前学習済みMask R-CNNを読み込む
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# numクラスで矩形領域を予測するためにモデルを変更
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# numクラスでセグメンテーションマスクを予測するためにモデルを変更
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model
4. augumentationの定義
- PILToTensor : PIL Imageをtorch.Tensorに変更
- ConvertImageDtype(torch.float) : torch.Tensorのdtypeを変更
- RandomHorizontalFlip(0.5) : 与えられたprobabilityによって、水平方向に反転。今回は0.5。
git clone https://github.com/pytorch/vision.git
cd vision
cp references/detection/utils.py ../
cp references/detection/transforms.py ../
cp references/detection/coco_eval.py ../
cp references/detection/engine.py ../
cp references/detection/coco_utils.py ../
cp ..
# augumentaionの定義
import transforms as T
def get_transform(train):
transforms = []
transforms.append(T.PILToTensor())
transforms.append(T.ConvertImageDtype(torch.float))
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
5. 学習
# 学習コード
import utils
from engine import train_one_epoch, evaluate
def main():
# cudaが使えるかどうか(使えない場合はcpu)
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
num_classes = 2 # 歩行者 or not
dataset = PennFudanDataset('PennFudanPed', get_transform(train=True))
dataset_test = PennFudanDataset('PennFudanPed', get_transform(train=False))
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=4, collate_fn=utils.collate_fn
)
data_loader = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=4, collate_fn=utils.collate_fn
)
model = get_model_instance_segmentation(num_classes)
model.to(device)
# 学習が必要なパラメーターを取得
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005) # weight_decay: L2正則化の係数
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
num_epochs = 10
for epoch in range(num_epochs):
# 1epochごとの学習。10回に1回、結果をprint。
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# 学習率の更新
lr_scheduler.step()
# testデータで評価
evaluate(model, data_loader_test, device=device)
print("That's it!")
return model
# 学習
model = main()
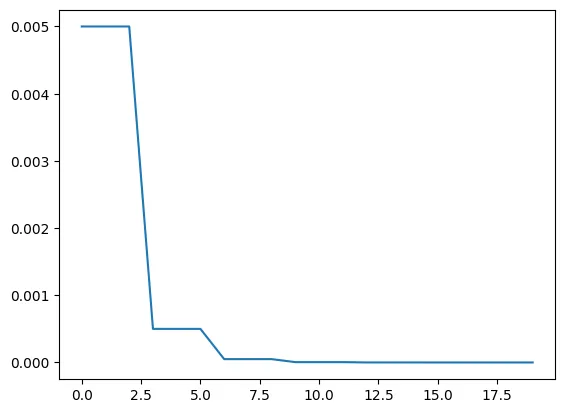
・torch.optim.lr_scheduler.StepLRとは…
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
- optimizer: 使用するoptimizerを指定。
- step_size: 何ステップ毎に学習率を更新するか。
- gammma: どれだけ減衰するか。
・torch.utils.data.DataLoaderのcollate_fnとは…
collate_fnはデータセットのリストを入力とします。そして、collate_fnの戻り値がDataLoaderから出力されるそうです。(詳しくはこちら。公式ドキュメントはこちら。)
今回の場合は、
collate_fn=utils.collate_fnとしているので、detection用のカスタマイズ関数を使用していると思われます。
6. 推論
# 推論コード
dataset_test = PennFudanDataset('PennFudanPed', get_transform(train=False))
model.cuda()
img, _ = dataset_test[-2] # インデックスは自由
# 評価モード
model.eval()
# 勾配計算なし
with torch.no_grad():
prediction = model([img.to('cuda')])
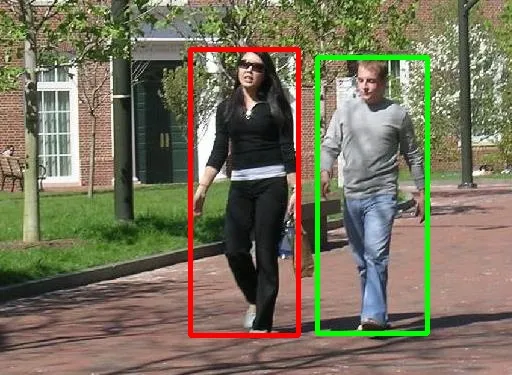
推論結果一例…




今西 渉
大阪大学大学院
生命機能研究科 卒業