【論文紹介】YOLOを読んでみた!
You Only Look Once: Unified, Real-Time Object Detection
物体検出といえば、「YOLO」ではないでしょうか。
今ではYOLOv8まで登場しており、有名なモデルとなっています。
そのため、ネットで検索するとたくさん情報が出てきます。コードも完備されており、簡単に使うことができます。
しかし、あまりYOLOについてあまり知らないなと思い、今回は「You Only Look Once: Unified, Real-Time Object Detection(YOLO)」を読んでみようと思います。
1. Abstract
YOLOは、一つのニューラルネットワークによって画像全体から直接バウンディングボックスとクラスの確率を予測するモデルとなっています。 検出パイプライン全体が単一のネットワークであるため、エンドツーエンドで最適化できます。 YOLOは、非常に高速なモデルとなっており、1秒あたり45フレーム処理できるそうです。モデルサイズを小さくしたFast YOLOは、さらに速く1秒あたり155フレーム処理するそうです。 また、位置特定のエラーを起こす確率は高くなっていますが、背景に対するfalse positive rateは低くなっています。 それだけでなく、汎化性能の高いモデルとなっています。
2. Introduction
YOLOの前に登場したR-CNNは、画像内に候補となるバウンディングボックス(矩形領域)を生成し、それらに対してCNNを適用して特徴量を抽出します。
その後、SVMを用いて候補となるバウンディングボックスに映っている物体のクラスを分類します。一つの物体に対して複数のボックスが検出された場合は、一つだけ残るように処理します。
このように複雑なパイプラインは遅く、各部分を個別に学習させる必要があるため最適化が難しいといった課題があります。
そこで、画像のピクセルから直接バウンディングボックスの座標とクラスの確率への単一の回帰問題を行うYOLOを構築しました。
画像を一度見るだけで、どの物体が存在し、どこにあるかを予測するため、「You Only Look Once」という名前が付けられました。おしゃれですね。
YOLOでは、単一のCNNが複数のバウンディングボックスとそれらのボックスに対するクラスの確率を同時に予測します。 YOLOはフルサイズの画像でトレーニングし、検出性能を直接最適化します。 以下メリットになります。
- 非常に高速:複雑なパイプライン不要。CNNのみ。
- 予測時に画像全体についてグローバルに推論:画像全体を見るため、クラスに関する文脈情報(周辺情報)を暗黙にエンコード。
→ 画像内の背景を物体と誤認識する可能性が低下 - 汎化性能向上:新しいドメインや予期せぬ入力に適用された場合でも影響を受けにくい
しかし、メリットだけでなく、デメリットもあります。 それは、高速に検出する能力と引き換えに、他の最先端の検出システムに比べて精度が劣っているということです。 特に小さいオブジェクトの正確な位置特定が苦手です。

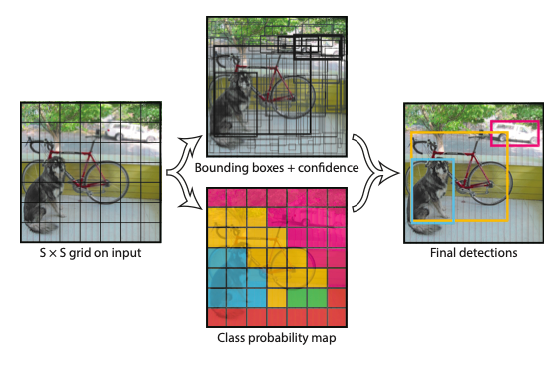
3. Unified Detection
YOLOは以下のような手順で物体を検出します。
1. 入力画像をSxSのグリッドに分割
物体の中心がグリッドセル内にある場合、そのグリッドセルはその物体の検出を担当。
2. 各グリッドセルにおいて、B個のバウンディングボックスとそれらのボックスの確信度スコア(Pr(Object)*IOU)を予測
確信度スコア:そのボックスがオブジェクトを含んでいるとどれだけ自信をもっているか
そのセル内に…
・オブジェクトが存在しない場合
→確信度は0(IOUが0であるため。IOUは後ほど解説。)
・オブジェクトが存在する場合
→予測されたボックスとground truthが重なり合う領域(IOU)と等しくなるように学習
各バウンディングボックスは5つの予測(x, y, w, h, confidence)で構成されます。
座標(x, y)は、バウンディングボックスの中心をグリッドセルの境界に対して相対的に表します。
幅(w)と高さ(h)は画像全体に対して相対的に予測されます。
3. 各グリッドセルはまた、C個の条件付きクラス確率Pr(Classi|Object)を予測
バウンディングボックスはB個予測するが、クラス確率は一つのみ。
テスト時には、条件付きクラス確率と個々のボックスの確信度予測を掛け合わせます。
以下の式から分かるように、各ボックスに対してクラス特有の確信度スコアを算出します。
この確信度スコアは、ボックス内にそのクラスが現れる確率と予測したボックスがどの程度オブジェクトに適合しているのかを含んでいます。
今回はS=7、B=2、C=20としているため、最終的な予測は、7x7x30(30=5x2+20)のテンソルになります。

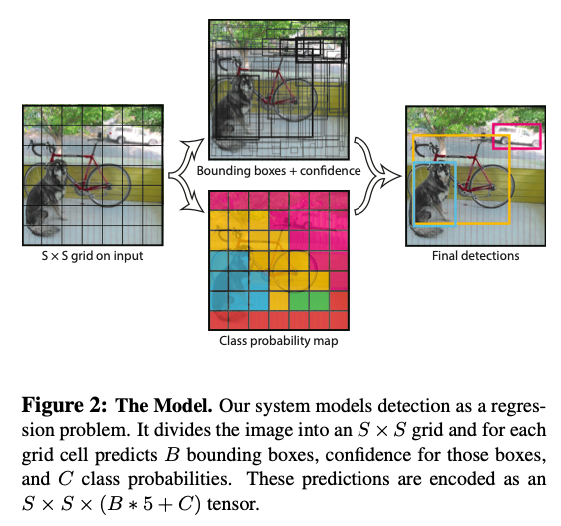
4. Network Design
YOLOはCNNで構成されており、畳み込み層で画像から特徴を抽出した後、全結合層によって確率と座標を予測します。
ネットワークアーキテクチャは、画像分類のためのGoogLeNetモデルに触発されています。
ネットワークには、24つの畳み込み層に続いて2つの全結合層があります。
GoogLeNetが使用するインセプションモジュールの代わりに、単純に1x1のconvの後に3x3のconvを使用しています。
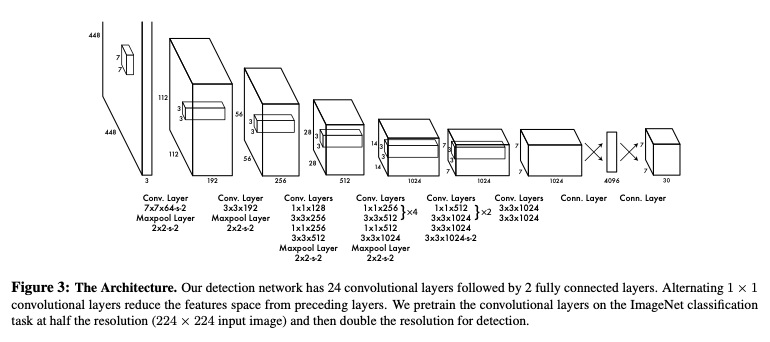
Inception moduleとは…
インセプションモジュールは、以下の図のように、異なるサイズのフィルターを持つ畳み込み層の組み合わせで構成される層になります。
見てもらうとわかると思うのですが、1x1、3x3、5x5といった異なるサイズのフィルターが並列に置かれています。
異なるサイズのフィルターを用いることで、様々なサイズで特徴抽出を行うことができるので、一種類のものよりも性能が高くなると考えられます。
単純に層を重ねた大きなモデルでは、過学習であったり勾配消失問題が発生してしまう可能性があるため、このように並列に置くことで工夫しています。
また、(b)を見てもらうと1x1のconvを挟んでいることがわかります。これによってパラメータの削減を図っています。
例えば、512チャネルの特徴マップに5x5フィルターを適用し64チャネルの特徴マップを出力する場合、5x5x512x64=819200となります。
これに1x1のフィルターを挟んで、24チャネルの特徴マップを出力する過程を追加すると、(1x1x512x24)+(5x5x24x64)=50688となります。
5. Training
学習時は、モデルの出力に対して二乗和誤差を最適化するようにしています。
二乗和誤差を使用するのは最適化が容易であるためですが、位置の誤差と分類の誤差を均等に重み付けしているため、理想的でない場合があります。
また、多くのグリッドセルがオブジェクトを含んでいない画像も存在します。そのため、これらのセルの確信度スコアがゼロに近づくようになり、
オブジェクトを含むセルからの勾配を圧倒してしまう可能性があります。
これはモデルの不安定性を引き起こし、トレーニングが早期に発散する原因となります。
この問題を解決するために、バウンディングボックスの座標予測の損失を増加させ、
オブジェクトを含まないボックスの確信度予測の損失を減少させます。
論文では、λcoord=5、λnoobj=0.5で重み付けします。
また、二乗和誤差は大きなボックスと小さなボックスの誤差を同じくらい重視します。
しかし、大きなボックスにおける小さな誤差は、小さなボックスにおける誤差よりも重要でないということを反映すべきです。
(大きなボックスにおいて誤差が小さいということは、ほとんど重なっているということ。もちろん小さなボックスにおいても小さすぎる誤差は十分に重なっていると考えられますが、そこまで重なっていない場合でも誤差が小さいと考えられます。)
これを部分的に解決するために、widthとheightをそのまま使うのではなく、平方根を取って計算します。
YOLOはグリッドセルごとに複数のバウンディングボックスを予測します。
トレーニング時ではすべてのバウンディングボックスを使うのではなく、各オブジェクトに対して代表のボックス(IOUの最も高いもの)を選択します。
これにより、predictorがより洗練され、全体的な再現率が向上します。
6. Limitations of YOLO
YOLOは、各グリッドセルが二つのボックスと一つのみのクラス(最大確率を採択するため)を予測するため、バウンディングボックス予測に強力な制約を課してしまいます。
これにより、モデルが予測できる近くのオブジェクトの数が制限されてしまいます。
具体的には鳥の群れなど、グループで現れる小さなオブジェクトに対してモデルは苦戦します。
また、新しいもしくは異常なアスペクト比や配置のオブジェクトに対して汎化するのが弱いといったデメリットもあります。
それだけでなく、複数のダウンサンプリングを使用していることから、比較的荒い特徴を使用してバウンディングボックスを予測します。(小さいものの検出は難しい??)
7. evaluation
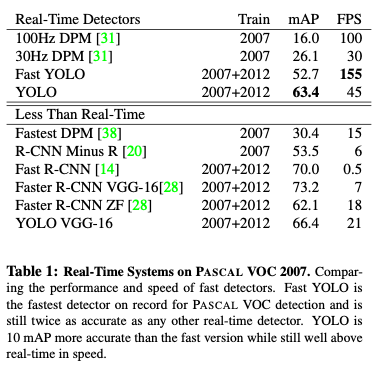
YOLOの性能評価を表したものがこちらになります。
mAPにおいてはYOLOがダントツで高く、FPSもかなり高い値をマークしています。
YOLOのベースネットワークをVGG-16にした場合、精度は上がりますが、その分処理が重たくなります。(それでも一秒間で21枚はすごい…)
精度的にはFast R-CNNやFaster R-CNNが良いものとなっていますが、実用的かと言われると難しいところはあります。(一秒間で7枚も状況によっては使えるかも)
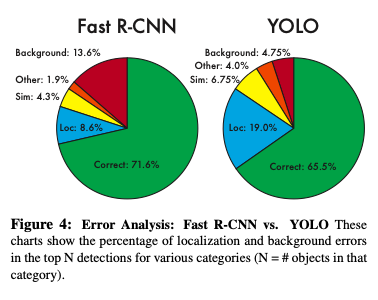
Figure 4はFast R-CNNとYOLOのエラーを比較したものになります。
YOLOは、エラーの中でlocalizationエラーが一番高くなっており、Fast R-CNNでは、Backgroundエラーが一番高くなっています。
このことから、YOLOは誤検出が少ない代わりに、正しく位置を特定できないといった課題があります。
それに対し、Fast R-CNNは検出性能が高い代わりに誤検出も多いということになります。
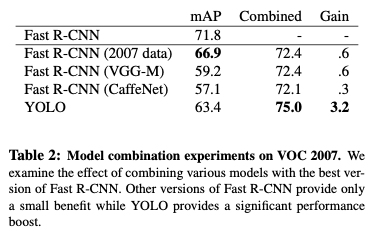
Combining Fast R-CNN and YOLO
ここで面白いのが、Fast R-CNNとYOLOを組み合わせると精度が上がるということになります。その結果が以下になります。
YOLOは、Fast R-CNNよりも遥かに背景の誤検出率が小さいモデルとなっています。そのため、YOLOを使用してFαst R-CNNから背景の検出を除去することで、性能が大幅に向上します。
具体的には、Fast R-CNNが予測する全てのバウンディングボックスに対して、YOLOが類似のボックスを予測しているかどうかを確認します。
もし類似のボックスが予測されている場合、その予測をYOLOが予測した確率と二つのボックスの重なりに基づいて強化します。
これは、Fast R-CNNとYOLOが異なる種類のエラーを起こすため、このような精度向上が見込めるということになります。
ただし、YOLOの高速処理を活かすことはできないため、これも状況によって使える手法となります。
YOLOは高速処理が可能なため、組み合わせてもそこまで処理時間が伸びるわけではありません。つまり、他のモデルを使用していてYOLOを組み合わせることにはかなり意味のあることだと思います。
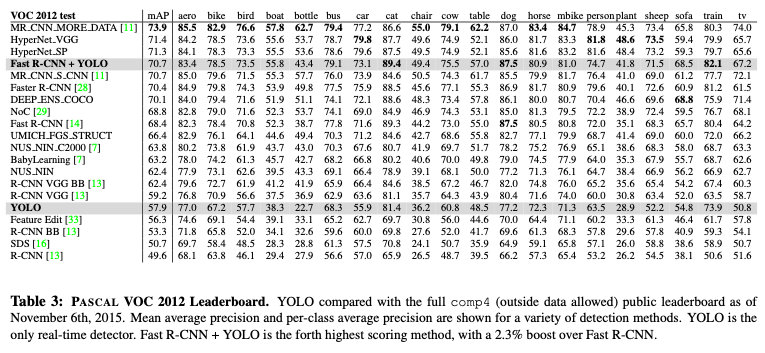
こちらの表は、VOC2012でテストした場合の結果になります。
YOLOは小さなオブジェクトの検出に苦戦しており、低いスコアをマークしています。
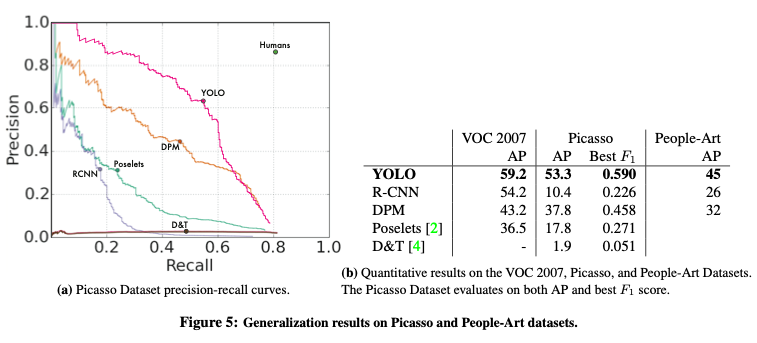
Generalizability: Person Detection in Artwork
最後に、YOLOのモデルがどれだけ汎用的なモデルかどうかを検証します。
あるデータセットで学習した後、他のデータセットで人物検出が可能かどうかを検証します。
VOC2007の場合は、学習後同データセットの人物検出、Picassoの場合は、VOC2012で学習、People-Artの場合はVOC2010で学習しています。(つまり、他のデータセットで学習して検出できるのか?って話です。)
R-CNNは、VOC2007の場合(学習とテストで同じデータセット)、高いAPをマークしていますが、絵画の場合は低い値をマークしています。
それに対してYOLOは高い値をマークしています。


今西 渉
大阪大学大学院
生命機能研究科 卒業