M1チップでMNISTを分類してみた!🍺
前回、「iMacに搭載されているAppleシリコン「M1チップ」で遊んでみた🍺」で画像生成にかかる時間を検証してみた。
あくまでも生成にかかる時間であり、これは推論時の時間である。Deep Learningで一番時間がかかる部分は学習であり、大きなモデルになればなるほどかかる時間は膨らんでいく。前回使用したStyleGANも2~3日は学習を回している(A100使用)。
そこで、「M1チップ」を使って学習を回してみたらどうなるのか。精度に影響はあるのか、時間はどうなのか、とても気になったので、今回は定番のMNISTを使って検証していく。(最新はM2チップなのに、まだM1チップなのかと思うかもしれないが、そこは目を瞑ってほしい。)
1. 仮想環境を作成し、pytorchをインストール
ターミナルを開き、自分の好きな作業フォルダで以下を実行。(もう既にpytorchをインストールしている環境があるのなら飛ばしてもらって構わない。)
python3 -m venv m1_venv source m1_venv/bin/activate pip3 install torch torchvision torchaudio
2. MNISTをダウンロード
pytorch tutorialを参考に、以下のようなdownload.pyを作成。
from pathlib import Path
import requests
import pickle
import gzip
import matplotlib.pyplot as plt
import numpy as np
# MNISTをダウンロード
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "https://github.com/pytorch/tutorials/raw/main/_static/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
with gzip.open((PATH/FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
plt.imshow(x_train[0].reshape((28, 28)), cmap="gray")
plt.savefig('sample.jpg')
このファイルを実行すると、mnist.pkl.gzがダウンロードされ、以下のような画像が生成される。
MNISTデータセットの一部
3. 使用するモデルを作成
今回は以下のようなモデルmodels.pyを作ってみた。pytorch tutorialではnn.Conv2dのみでモデルを作成していたが、nn.Conv2dとnn.Linearを使ったよくあるモデルを作ってみた。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MnistModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3)
self.conv2 = nn.Conv2d(16, 16, kernel_size=3)
self.dense1 = nn.Linear(400, 256)
self.dense2 = nn.Linear(256, 64)
self.dense3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 1, 28, 28)
x = F.relu(self.conv1(x))
x = F.avg_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.avg_pool2d(x, 2)
x = x.view(-1, 400)
x = F.relu(self.dense1(x))
x = F.relu(self.dense2(x))
x = self.dense3(x)
return x
4. 学習部分
最後に学習する部分main.pyを作成。特に難しいことはせず、lossとaccuracyを描画するようなコードにした。また、タスクに対して十分すぎるモデルを作ったような気がしたので、エポック数は小さく設定した。最終的に、訓練にかかった時間をグラフのタイトルに設定(どこに書いているんだ)。
import time
from pathlib import Path
import pickle
import gzip
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn.functional as F
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
from models import MnistModel
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
FILENAME = "mnist.pkl.gz"
# MNISTデータセットをロード
with gzip.open((PATH/FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
n, c = x_train.shape
# データセット作成
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=64, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=64)
model = MnistModel()
model = model.to('mps')
criterion = F.cross_entropy
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
train_loss = []
val_loss = []
accuracy = []
start = time.time()
for epoch in range(10):
print('-----------------------------------')
print(f'epoch {epoch}:')
running_loss = 0
model.train()
for image, label in train_dl:
image = image.to('mps')
label = label.to('mps')
optimizer.zero_grad()
output = model(image)
loss = criterion(output, label)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss.append(running_loss / len(train_dl))
print(f'train loss : {running_loss / len(train_dl)}')
running_loss = 0
running_acc = 0
model.eval()
for image, label in valid_dl:
image = image.to('mps')
label = label.to('mps')
with torch.no_grad():
output = model(image)
loss = criterion(output, label)
predict = torch.argmax(output, dim=1)
running_acc += (predict == label).float().mean().item()
running_loss += loss.item()
val_loss.append(running_loss / len(valid_dl))
accuracy.append(running_acc / len(valid_dl))
print(f'val loss : {running_loss / len(valid_dl)}')
print(f'acc : {running_acc / len(valid_dl)}')
torch.save(model.state_dict(), 'model.pt')
end = time.time()
fig = plt.figure()
plt.plot(range(1, 11), train_loss, label='train')
plt.plot(range(1, 11), val_loss, label='val')
plt.plot(range(1, 11), accuracy, label='acc')
plt.title(f'training_time : {end-start}')
plt.xlabel('epochs')
plt.legend()
plt.savefig('result.jpg')
5. 結果
タスクが簡単すぎるのか、それともモデルが大きすぎたのか、1epochのtrainで高い精度が出てしまっている。その後は僅かにだが精度は向上している。validation lossをみてもらうとわかるのだが、すぐに収束(もしくは振動)しているため、これ以上学習すると過学習を起こす可能性があるため、ある意味10epochsでよかったのかもしれない。
本題の学習時間は50.59秒だった。それに対しCPUは、92.57秒。
M1チップ(GPU)であれば、40秒も短縮することができる。今回は10epochsだったが、もっとたくさん学習させる場合、大きな差が開くと考えられる。
やはりM1チップ(GPU)はCPUに比べて優秀なのか。やはりNVIDIAみたいな高価なGPUは持っていないMacユーザーでもある程度Deep Learningを楽しめるのかもしれない。
今後のAppleに期待である。
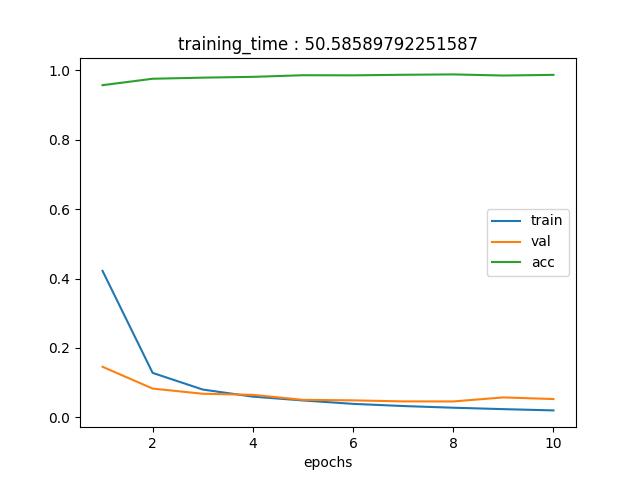
M1チップ(GPU)を使って学習
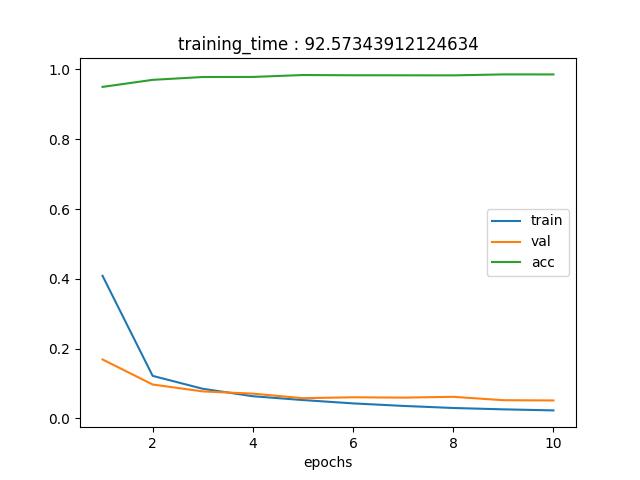
M1チップ(GPU)を使って学習

今西 渉
大阪大学大学院
生命機能研究科 卒業